
Getting Help From AI to Tag Sentences
I’ve recently announced a new feature I call “tags” – keywords, shown on the left of the sentences, including names of specific arguments, theories, -isms, etc. which don’t appear in the sentence itself. Tagging, I had said, was an ongoing manual process I’d been carrying out for some time. I had tagged 525 sentences myself by going through the total of 1603 using the wet, mushy neural networks in my brain.
Even though I have intentionally avoided using any kind of automatization for my editorial work in this project since the beginning, I got curious about the kind of help I could get from AI applications for the relatively easy task of tagging sentences. So I plugged OpenAI’s Generative Pre-trained Transformer 3 (GPT-3) into my database.
GPT-3 is “an autoregressive language model with 175 billion parameters, 10× more than any previous non-sparse language model”. It is described as “one of the most interesting and important AI systems ever produced” by David Chalmers, currently the youngest (56) living philosopher listed in my project. GPT-3 has an API which returns a completion for any text prompt you give, attempting to match the pattern. The prompt I designed for the task went like this:
Sentence: There are two kinds of substance: mind (which I am as a conscious being; ‘res cogitans’) and matter (‘res extensa’).
Category: Dualism
Sentence: There are no innate certainties to be discovered in our minds, all knowledge comes from experience.
Category: Empiricism
Sentence: The universe consists of matter in motion, and nothing else exists; it is a vast machine.
Category: Materialism
Sentence: …
Category
Thanks to this prompt and a few parameter settings, GPT-3 was able to “understand” what I was asking from it and to work just as I intended it to: it read the prompt and produced completions to it 1603 times, each time with a different sentence from my collection substituting the “…” in the prompt (thanks to a function I created in Google Sheets Apps Script based on Richman’s), thus offering 1603 suggestions for categories. But how successful was it, from a human point of view?


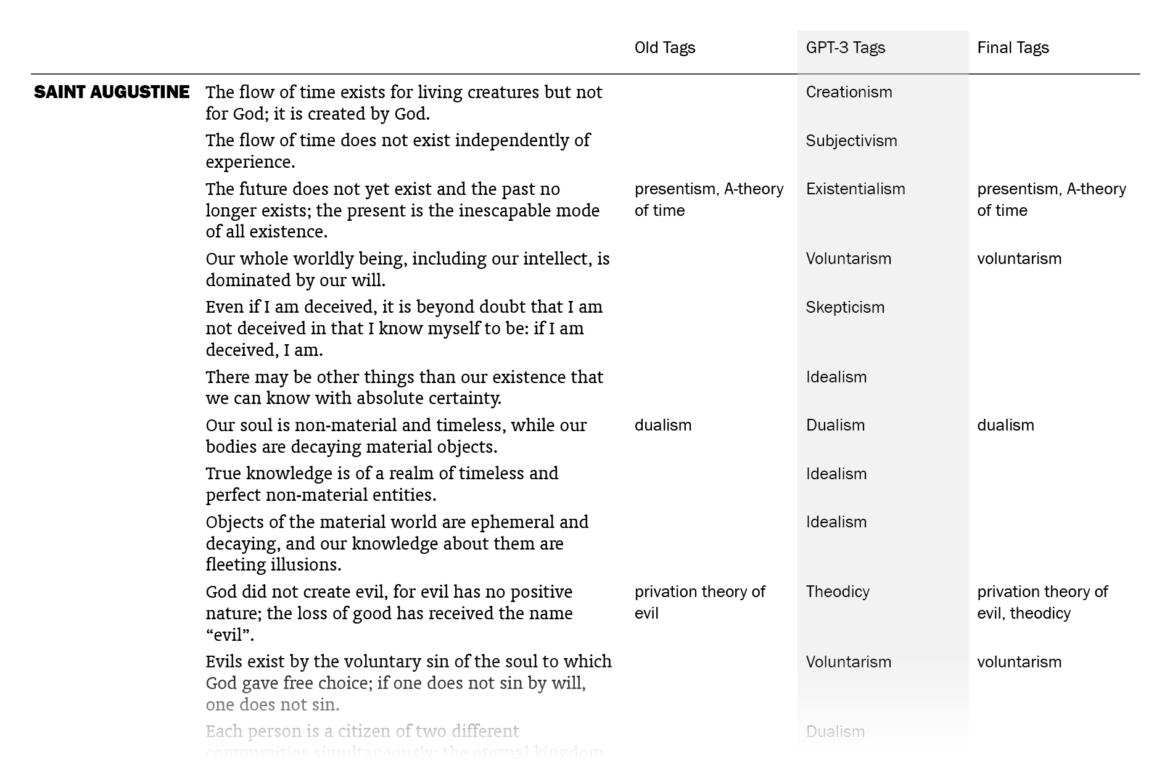

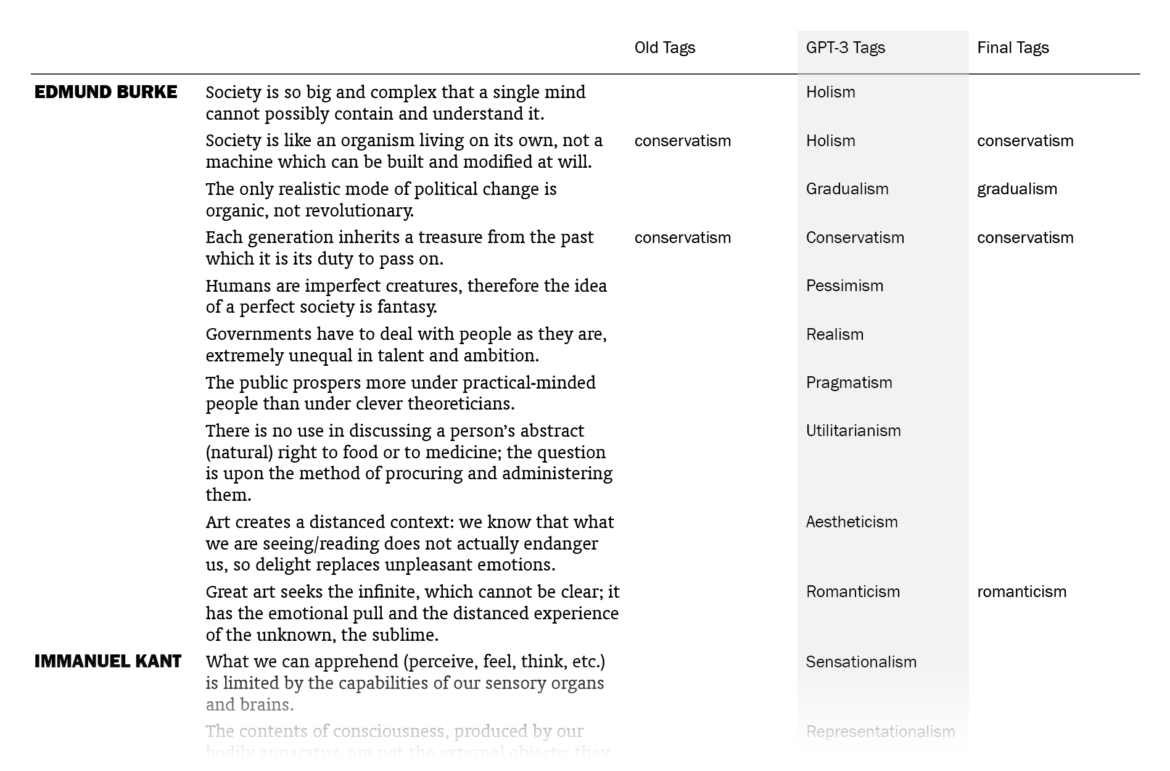
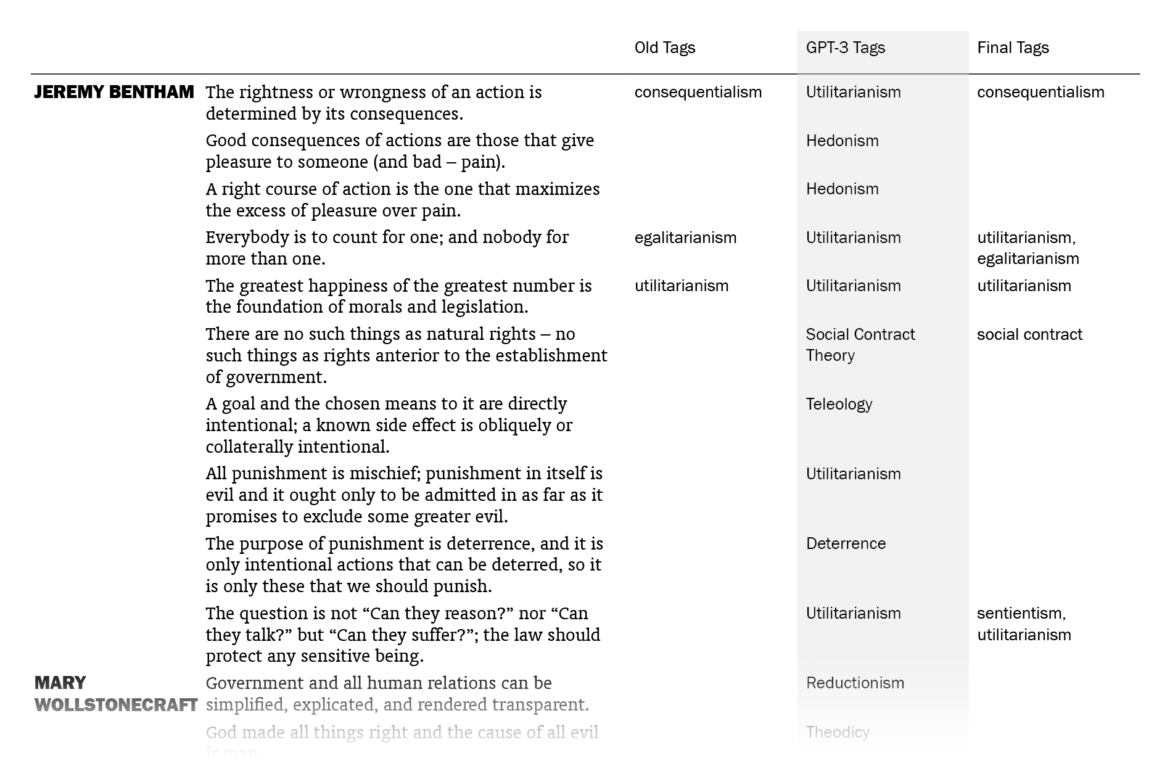
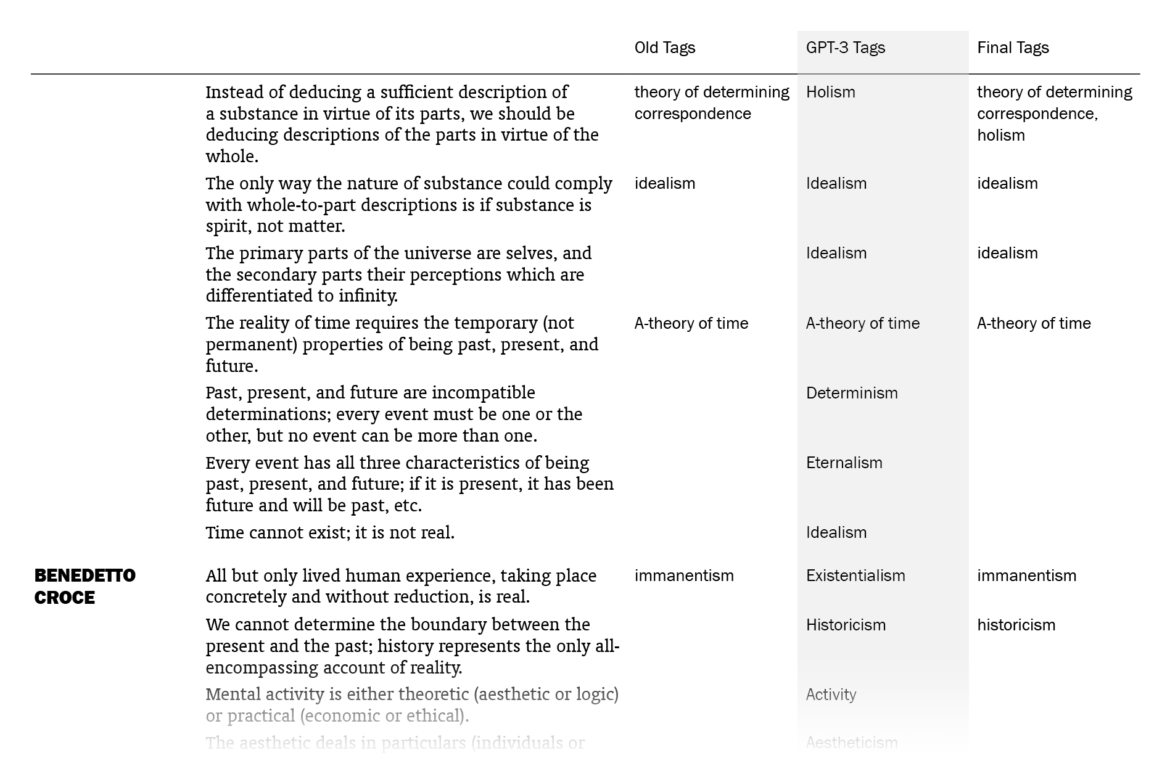
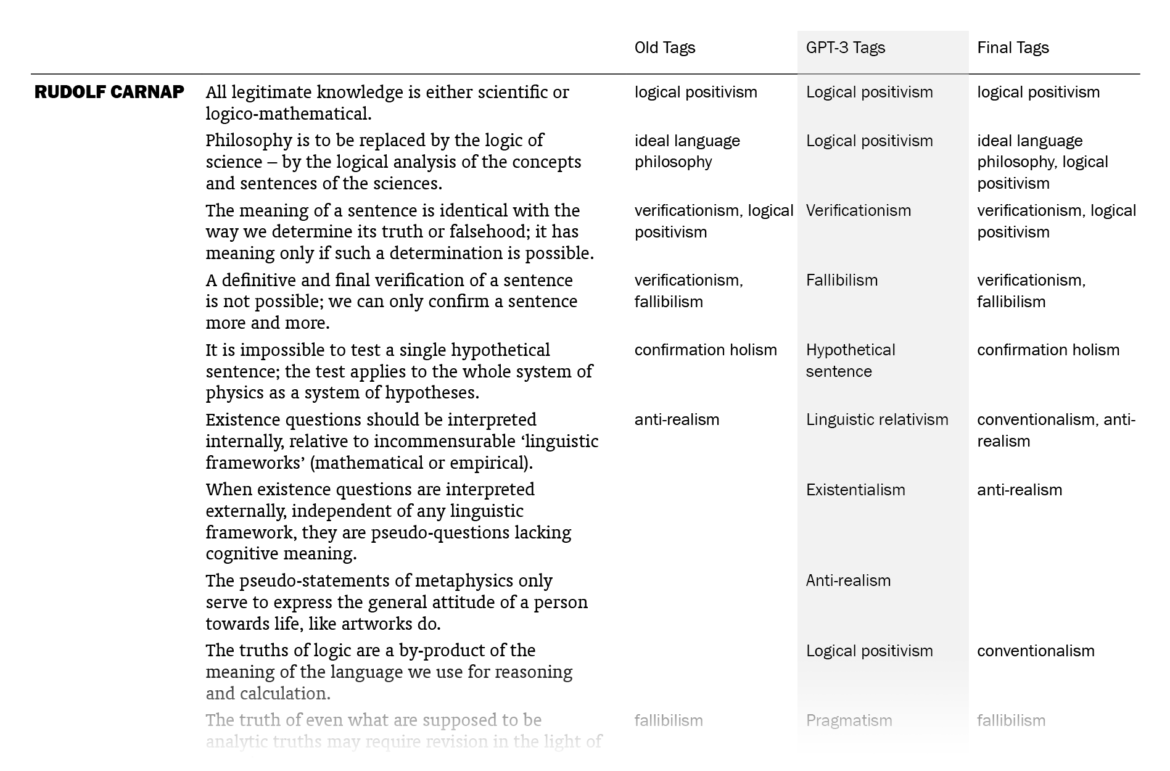


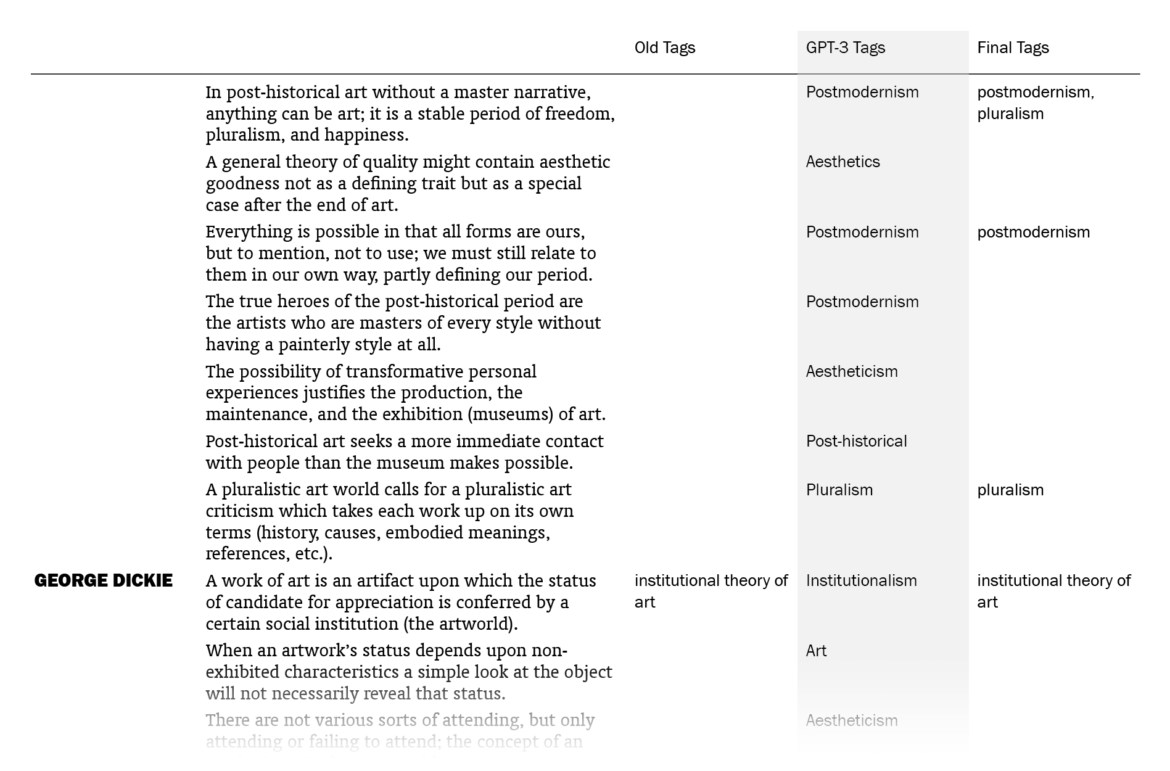
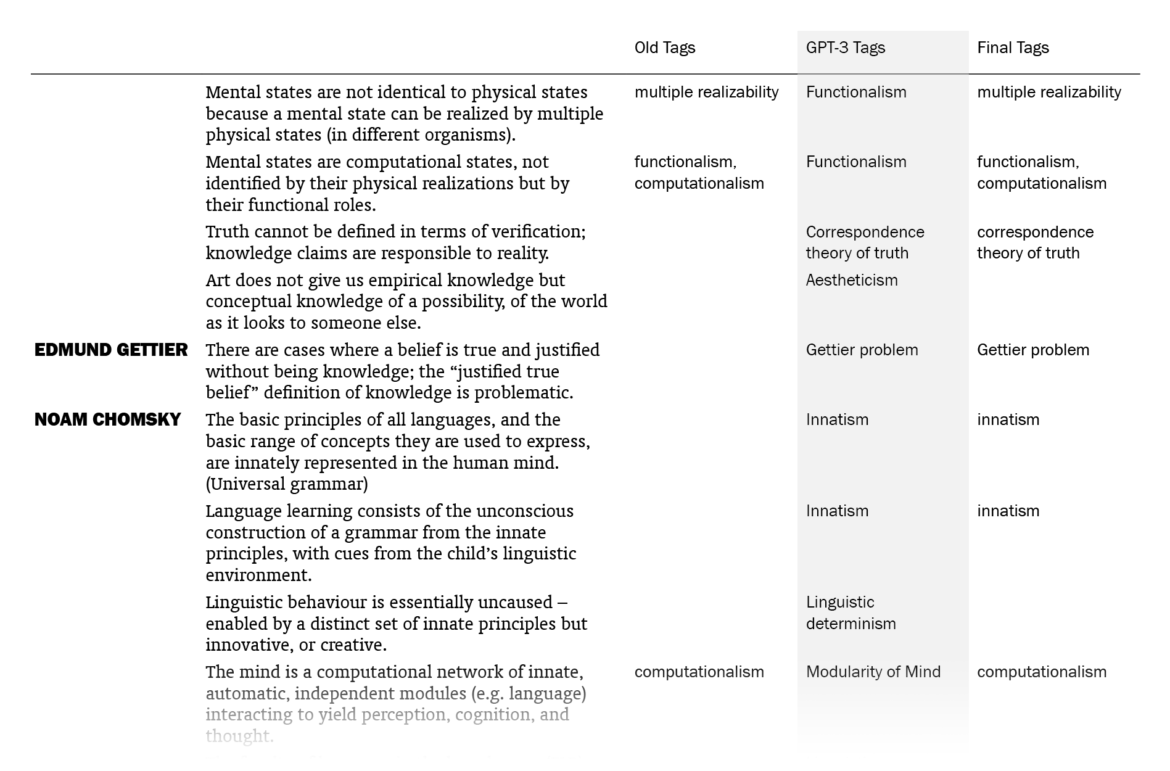
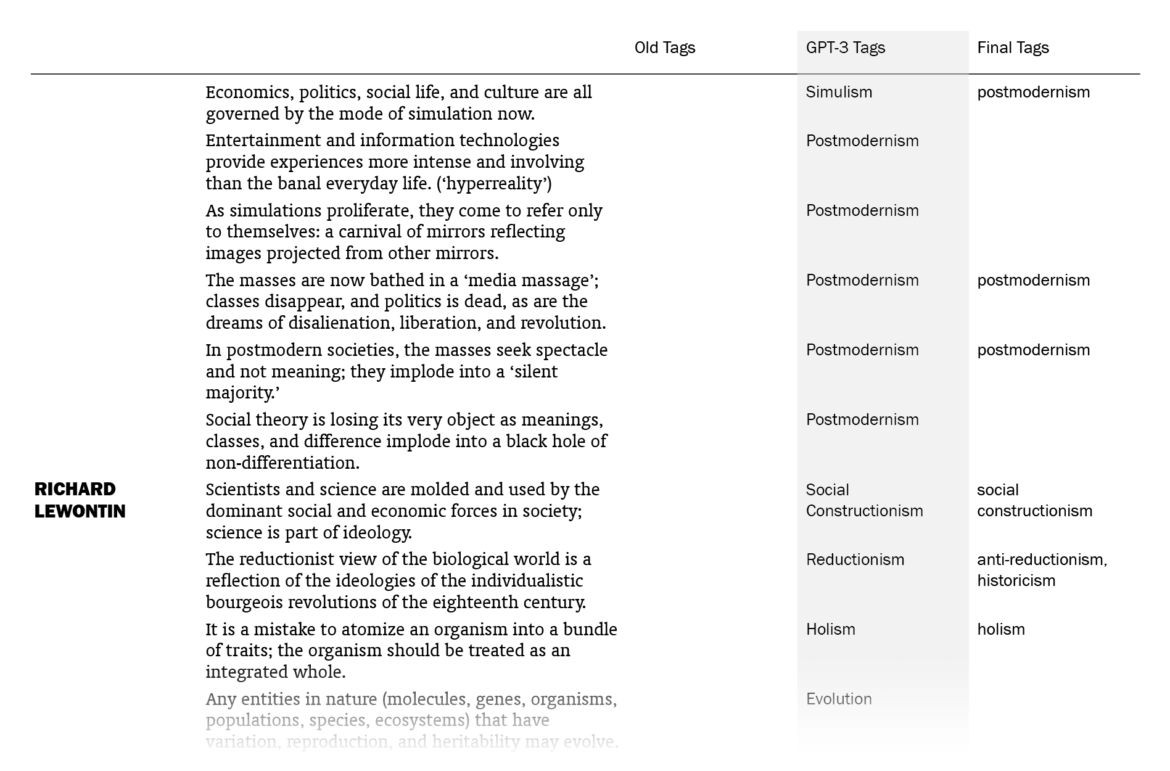
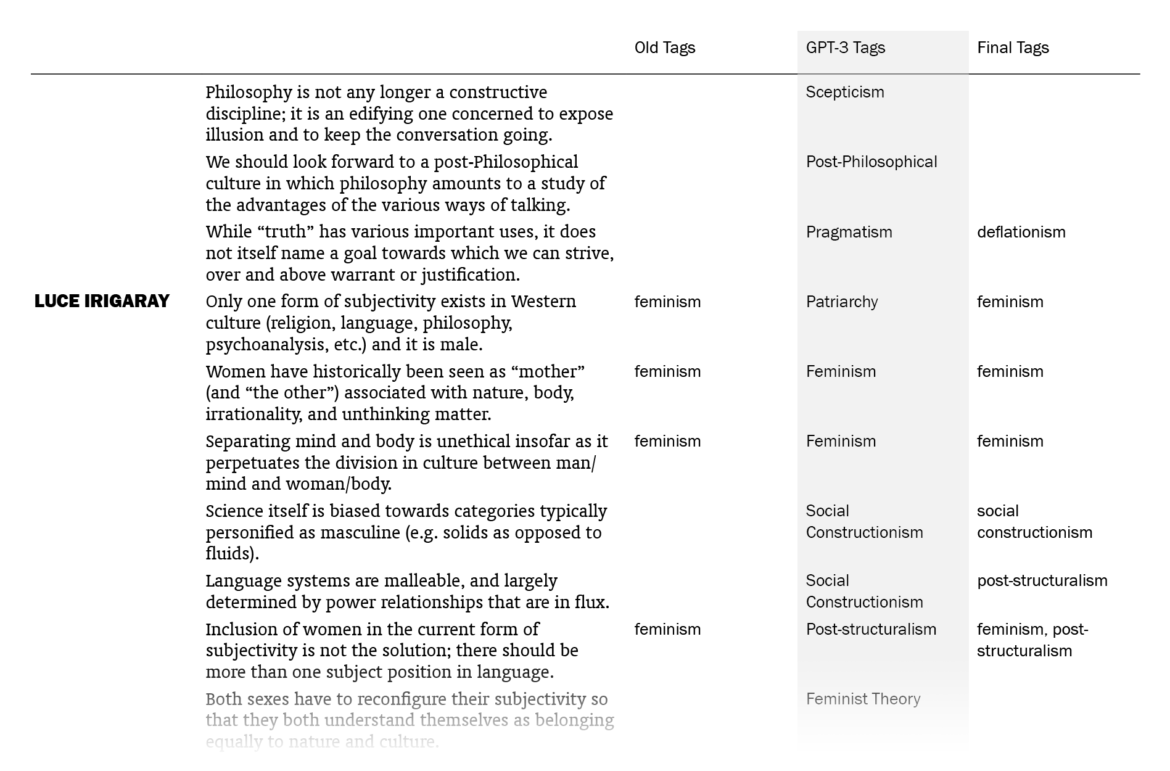
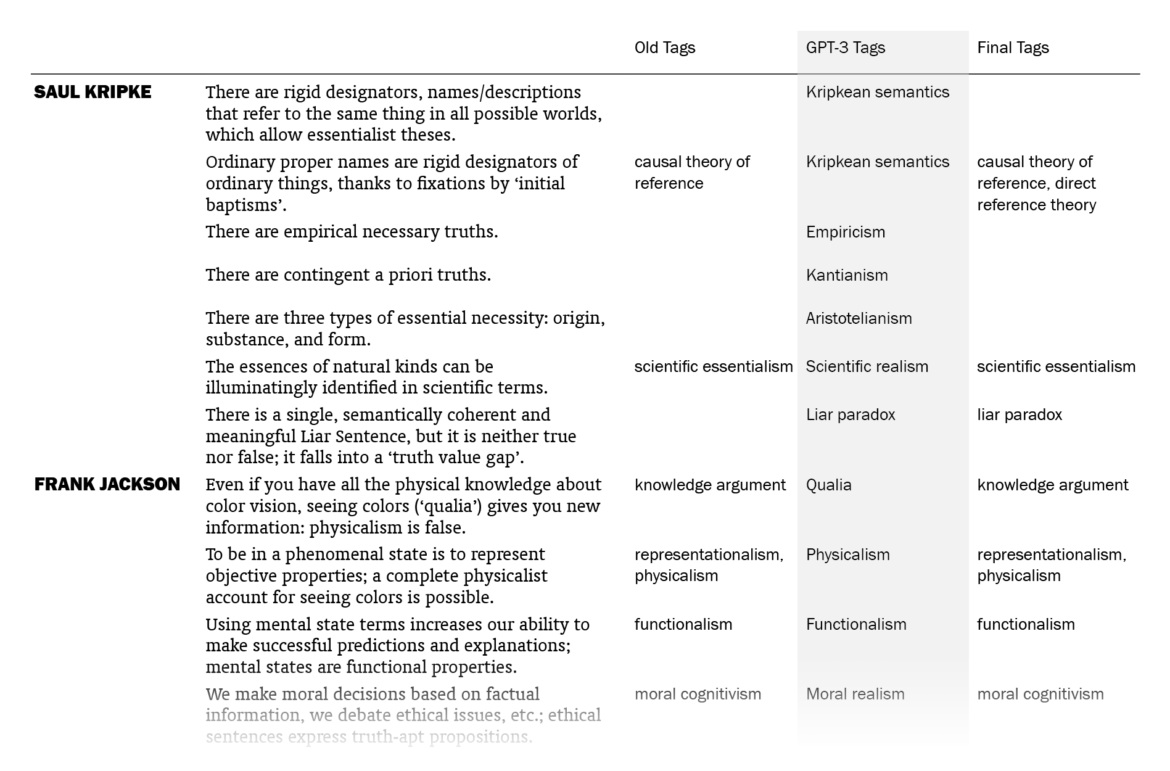
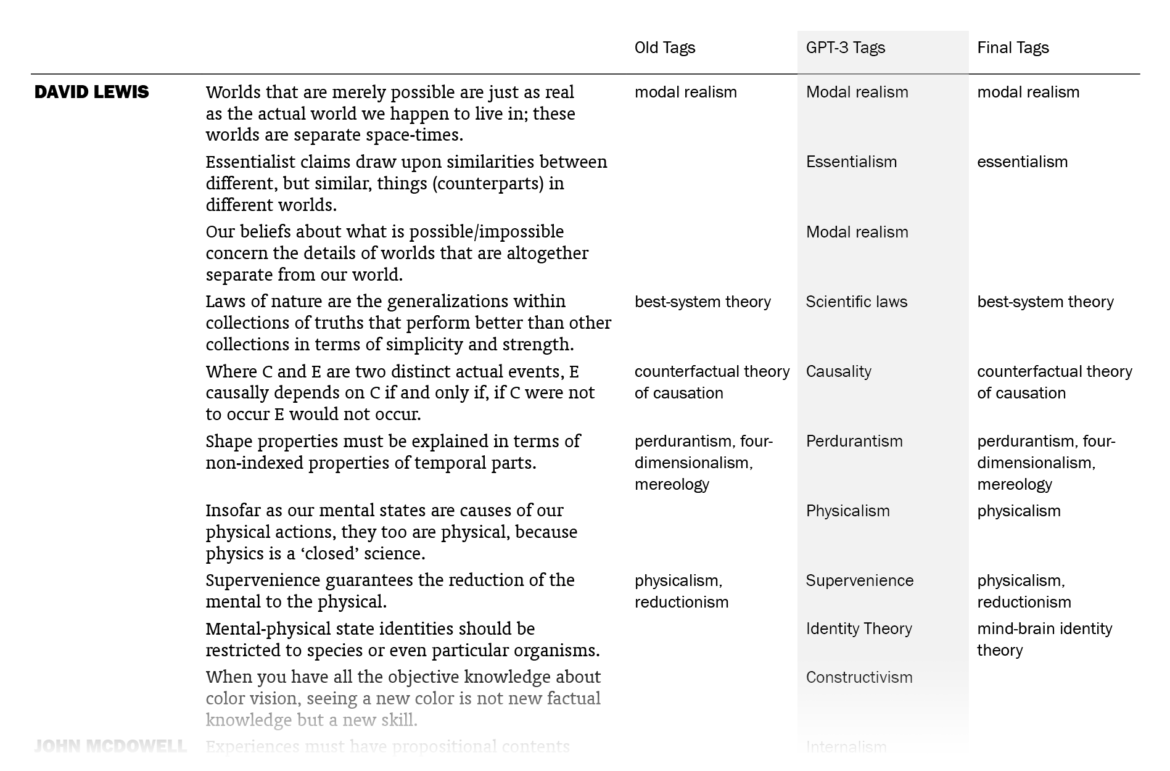
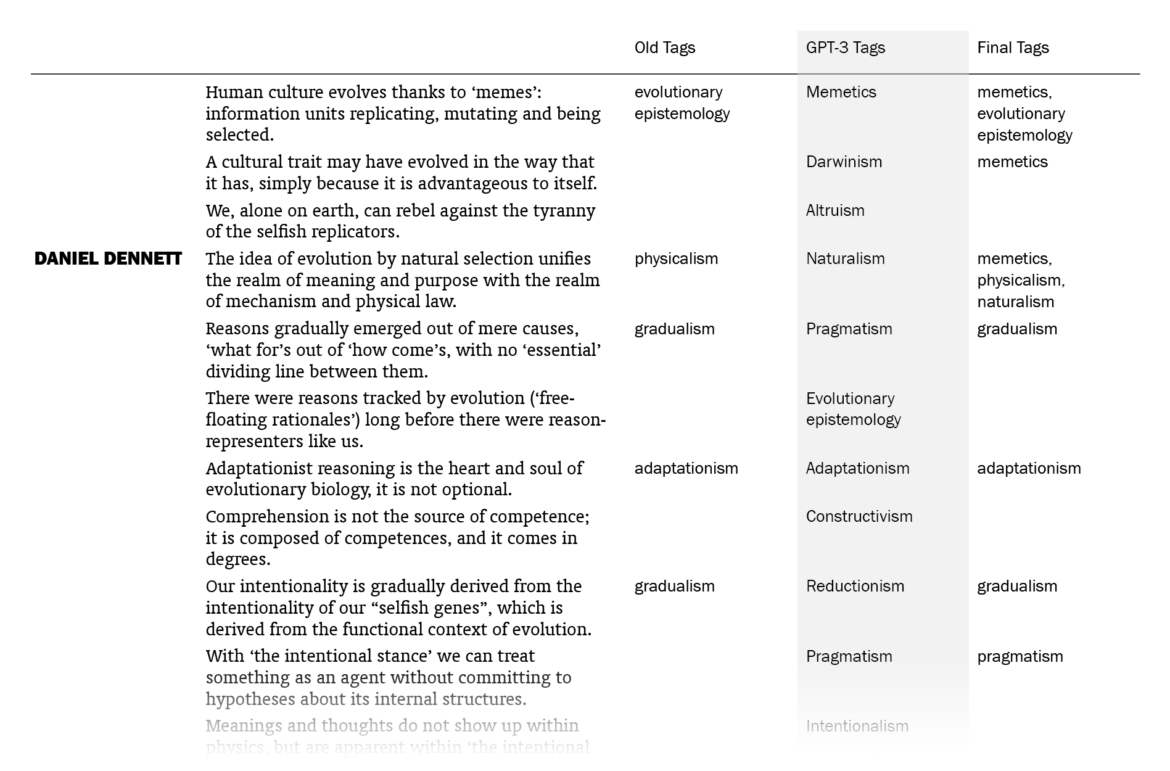
Overall, I was impressed. Out of the 525 sentences that I myself had already tagged, GPT-3 suggestions matched 178 (33.9%). (This means that my old tags, which might be more than one for a sentence, included the ones by GPT-3 for 178 sentences. Note that it didn’t know what my old tags were except for the few in the prompt.) I put GPT-3’s suggestions in a column next to my tags and sentences, went through the 1603 lines one by one (two times) and made additions to my tags where the suggestions made sense to me. In the end, the total count of tagged sentences went from 525 up to 705. I made changes in the tags of 242 sentences, mostly thanks to GPT-3 – I want to explain “mostly” here.
I noticed three different ways in which GPT-3 influenced me to add tags:
- GPT-3 suggesting terms I was not familiar with / would not think of by myself (rare)
- GPT-3 suggesting terms I was familiar with but hadn’t thought of as tags previously
- GPT-3 suggesting terms I had thought of as tags before but wasn’t sure enough to add, thus encouraging me to add them
The fact that 242 sentences had additions to their tags with this procedure doesn’t mean they were all directly suggested by GPT-3: going through the 1603 sentences again and again in order to compare with the suggested tags, I had moments of coming up with new tags myself, independently of GPT-3’s suggestions. There were also cases where I took a suggestion by GPT-3 for a sentence and used it for other sentences (with different GPT-3 tags), sometimes excluding the original sentence it suggested the tag for. The number of cases where I implemented (with/without adjustments) a GPT-3 suggestion specifically made for that sentence is 157; if we include its indirect influences where I took its suggestions and applied to other sentences, we can say that the total number of sentences to which I added tags thanks to GPT-3 is 186, which amounts to 11.6% of the sentences.
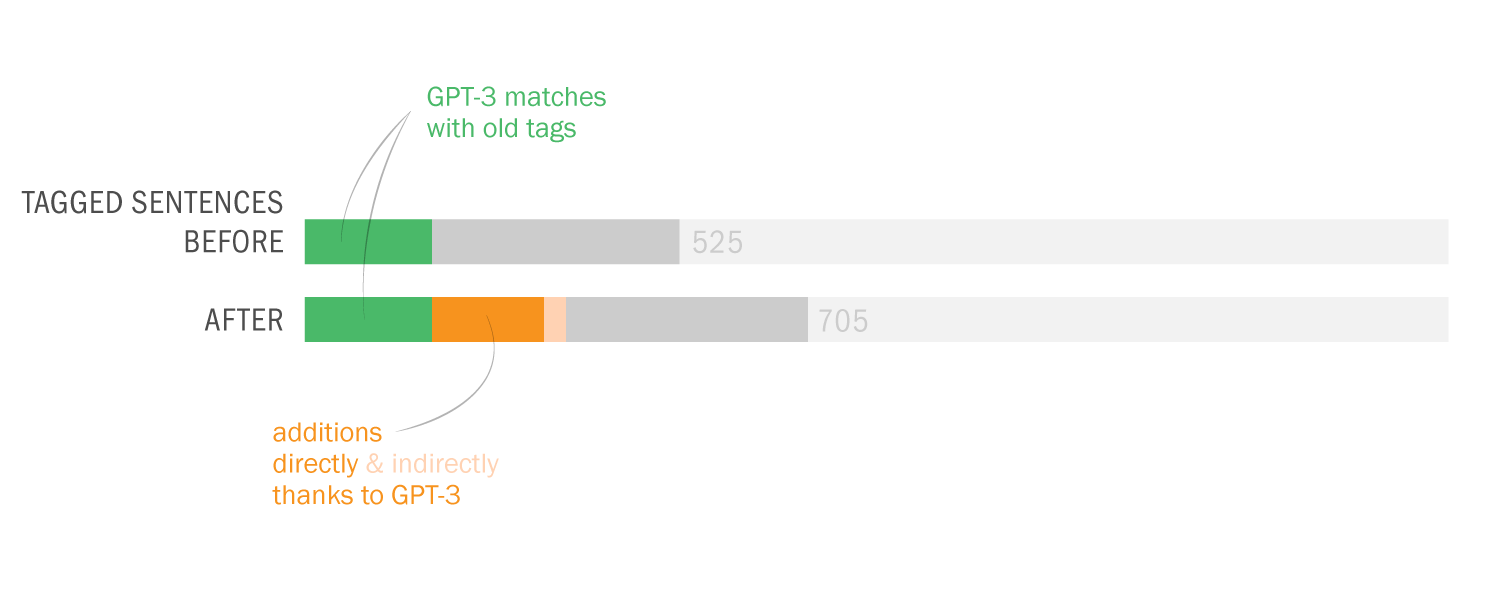
So the help I got from GPT-3 was not exactly new information to me but mostly nudges here and there, making me remember/appreciate or convincing me about some terms as tags, for the 11.6% of the sentences. You may be unimpressed when it’s phrased like this but this was just the kind and the amount of contribution I was hoping for, since I had already done the bulk of the work myself. And I’m grateful to be able to get such help with editorial work in philosophy with this small amount of money ($5) and effort (designing a prompt and creating a function in Sheets, without the need for training a custom model) this quickly (less than a minute to run for the 1603 sentences).
To be sure, the numbers of additions above are dependent on the criteria of my project and they widely underestimate GPT-3’s success because there are many cases where:
- GPT-3 suggests accurate information that just doesn’t fit into my definition of tags for this project: it correctly identifies names of philosophers or -isms generated from them (e.g. Kant or Kantianism for Kant’s own sentences), or suggests accurate terms that I find not precise (i.e. interesting) enough for my tags (e.g. theism).
- GPT-3 suggests one correct tag for the majority of a philosopher’s sentences (e.g. existentialism for Heidegger’s) but I choose to act stingy in those cases by tagging just a few sentences that best represent the -ism in question.
- GPT-3 suggests an okay tag (e.g. existentialism for sentences by Camus) but I have a more accurate/precise one (absurdism) so I don’t change it.
- GPT-3 makes a good suggestion capturing the idea in the sentence, but it would be historically inappropriate to use that tag for that philosopher. (Remember, it doesn’t know who the sentences belong to.)
- GPT-3 gets a keyword right, but the sentence actually disputes that argument/theory/-ism, so I don’t want to use it as a tag misrepresenting the position of that sentence.
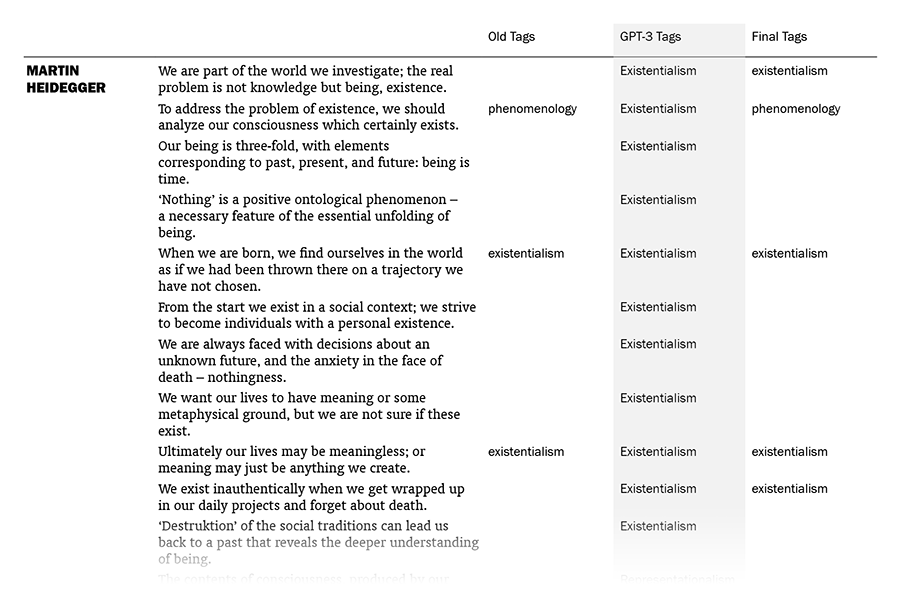{kind=link}
If we count positive cases such as these – if we count all GPT-3’s good guesses, ignoring their precision, historical awareness, and usefulness with regard to my specific editorial standards and choices – the success rate of GPT-3 becomes 71.4%! (1144 sentences out of 1603) (Yes, I did another round just to determine this number. I was that curious.)
I also got another type of corroboration by GPT-3 for my previous efforts of tagging: for the majority of the sentences for which I had little hope of coming up with useful tags, GPT-3 also fails to offer them. It either suggests generic terms (e.g. aesthetics for sentences about various positions in aesthetics, which actually is a whole branch in the Filters in the Menu) or terms that I could not relate to the sentence (idealism is one of its favorite wild cards). This confirms what I had written in the previous post, that not every sentence is suitable for tagging.
We can highlight three numbers to sum up the situation from my and GPT-3’s perspectives:
- The actual help I got from GPT-3 (direct + indirect additions): 11.6% (186 sentences)
- The strict success rate of GPT-3 by my standards (direct additions + matches): 20.9% (335 sentences)
- The relaxed success rate of GPT-3 (good guesses): 71.4% (1144 sentences)
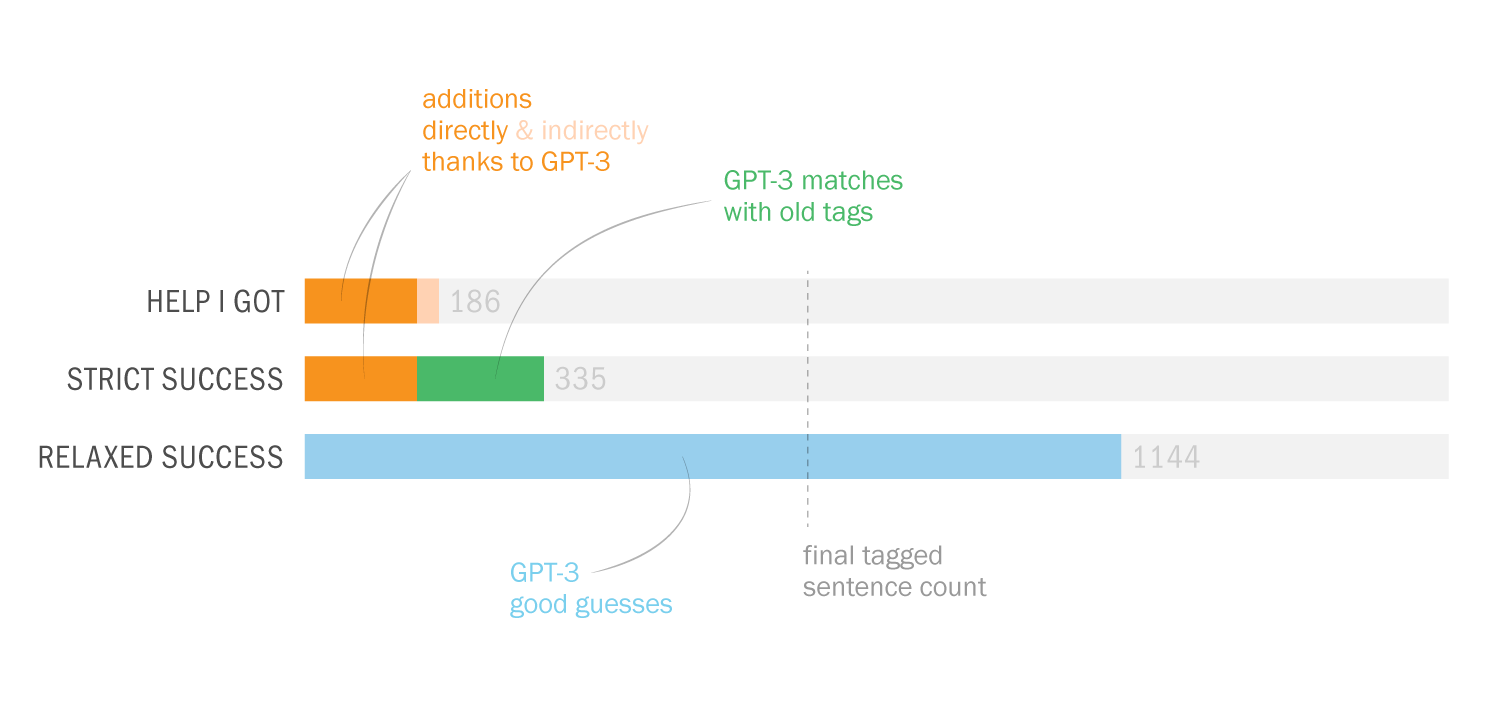
Please keep in mind, while looking at all these numbers, that there might well be instances where I’ve misconstrued a good suggestion by GPT-3 and haven’t used/counted it – I’m human! – but I believe these figures are good rough measures to get a grasp of its competence for a task like this. It is also worth noting that the final number of tagged sentences (705) could be given some weight here when judging GPT-3’s (and my) success at tagging: since not every sentence is (objectively or project-specifically) suitable for tagging, maybe the numbers should be proportioned to 705 instead of 1603 – making the strict success rate of GPT-3 by my standards (335 sentences) jump from 20.9% to 47.5%. Of course I don’t believe 705 is really the final number and no other sentence can be tagged in a meaningful way (I’ve already done a few changes/additions since I wrote this post) but this calculation may contribute to a more balanced picture at this stage.
Witnessing its usefulness first-hand, I wanted to write this detailed post as (1) a documentation of GPT-3’s modest contribution to my project and (2) an evaluation of GPT-3’s impressive capabilities for tasks like these. I agree now more than before that people are not overstating it when they call it a revolution and I’m sure many of you will soon be benefiting from systems like these especially when they will be readily integrated into basic software that we use daily.